728x90
Iris 데이터 분류
1. Logistic Regression
2. Support Vector Machine
3. Random Forest
4. Naïve Bayes Classification
5. Decision Tree
1. Logistic Regression
Iris 를 불러와서 x,y 값을 정의해주고 train / test분리하는 이 '더보기'부분은 5가지 모델 작성 방법 모두 동일하다.
<동일 앞부분>
더보기
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection._split import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
iris = datasets.load_iris() # Iris 데이터 불러오기
print(iris.data[:3])
print(np.corrcoef(iris.data[:, 2], iris.data[:, 3])) # 상관관계 보기
"""
[[1. 0.96286543]
[0.96286543 1. ]]
"""
x = iris.data[:, [2, 3]] # feature(독립변수, x) : petal length, petal width
y = iris.target # label, class
print(type(x), type(y), x.shape, y.shape) # x는 2차원(150, 2) y는 1차원(150,)
print(set(y)) # {0, 1, 2}
print('-----------------train / test 분리 - 오버피팅(과적합)방지-----------------------')
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state = 0)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (105, 2) (45, 2) (105,) (45,)
# scaling(표준화)
print(x_train[:3])
sc = StandardScaler()
sc.fit(x_test)
sc.fit(x_train)
x_train = sc.transform(x_train)
x_test = sc.transform(x_test) # 표준화 완성
print(x_train[:3])
# 표준화 값을 원래 값으로 복귀
# inver_x_train = sc.inverse_transform(x_train)
# print(inver_x_train[:3])
Logistic Regression 모델 작성 부분
# 분류 모델
# logit(), glm() : 이항분류 - 활성화 함수 - sigmoid
# LogisticRegression : 다항분류 - 활성화 함수 : softmax
model = LogisticRegression(C = 1.0, random_state = 0)
# C속성 : 분류정확도를 조절하기 위해 모델에 패널티를 적용(L2정규화)-과적합 방지
model.fit(x_train, y_train) # 지도학습이니까
모델을 만들고 나서 분류 예측, 표준화, 차트그리기를 하는 이 '더보기'부분은 5가지 모델 작성 방법 모두 동일하다.
<동일 뒷부분>
더보기
# 분류 예측
y_pred = model.predict(x_test) # 검정자료는 test
print('예측값 : ', y_pred)
print('예측값 : ', y_test)
# 분류 정확도
print('총 개수 : %d, 오류수 : %d'%(len(y_test), (y_test != y_pred).sum()))
print()
print('분류 정확도 출력1 : %.3f'%accuracy_score(y_test, y_pred))
con_mat = pd.crosstab(y_test, y_pred, rownames = ['예측치'], colnames=['실제치'])
print(con_mat)
print('분류 정확도 출력2 : ', (con_mat[0][0] + con_mat[1][1] + con_mat[2][2]) / len(y_test))
print('분류 정확도 출력3 : ', model.score(x_test, y_test))
print('분류 정확도 출력4 : ', model.score(x_train, y_train))
# 새로운 값으로 예측
new_data = np.array([[5.1, 2.4], [1.1, 1.4], [8.1, 8.4]])
# 표준화
sc.fit(new_data)
new_data = sc.transform(new_data)
new_pred = model.predict(new_data)
print('새로운 값으로 예측 : ', new_pred) # 새로운 값으로 예측 : [1 0 2]
#* 붓꽃 자료에 대한 로지스틱 회귀 결과를 차트로 그리기 *
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib import font_manager, rc
plt.rc('font', family='malgun gothic')
plt.rcParams['axes.unicode_minus']= False
def plot_decision_region(X, y, classifier, test_idx=None, resolution=0.02, title=''):
markers = ('s', 'x', 'o', '^', 'v') # 점 표시 모양 5개 정의
colors = ('r', 'b', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#print('cmap : ', cmap.colors[0], cmap.colors[1], cmap.colors[2])
# decision surface 그리기
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 0].min() - 1, X[:, 0].max() + 1
xx, yy = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
# xx, yy를 ravel()를 이용해 1차원 배열로 만든 후 전치행렬로 변환하여 퍼셉트론 분류기의
# predict()의 인자로 입력하여 계산된 예측값을 Z로 둔다.
Z = classifier.predict(np.array([xx.ravel(), yy.ravel()]).T)
Z = Z.reshape(xx.shape) # Z를 reshape()을 이용해 원래 배열 모양으로 복원한다.
# X를 xx, yy가 축인 그래프 상에 cmap을 이용해 등고선을 그림
plt.contourf(xx, yy, Z, alpha=0.5, cmap=cmap)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
X_test = X[test_idx, :]
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl, 0], y=X[y==cl, 1], c=cmap(idx), marker=markers[idx], label=cl)
if test_idx:
X_test = X[test_idx, :]
plt.scatter(X_test[:, 0], X_test[:, 1], c=[], linewidth=1, marker='o', s=80, label='testset')
plt.xlabel('꽃잎 길이')
plt.ylabel('꽃잎 너비')
plt.legend(loc=2)
plt.title(title)
plt.show()
x_combined_std = np.vstack((x_train, x_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_region(X=x_combined_std, y=y_combined, classifier=model, test_idx=range(105, 150), title='scikit-learn제공')

2. Support Vector Machine
<동일 앞부분>
더보기
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection._split import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
iris = datasets.load_iris() # Iris 데이터 불러오기
print(iris.data[:3])
print(np.corrcoef(iris.data[:, 2], iris.data[:, 3])) # 상관관계 보기
"""
[[1. 0.96286543]
[0.96286543 1. ]]
"""
x = iris.data[:, [2, 3]] # feature(독립변수, x) : petal length, petal width
y = iris.target # label, class
print(type(x), type(y), x.shape, y.shape) # x는 2차원(150, 2) y는 1차원(150,)
print(set(y)) # {0, 1, 2}
print('-----------------train / test 분리 - 오버피팅(과적합)방지-----------------------')
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state = 0)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (105, 2) (45, 2) (105,) (45,)
# scaling(표준화)
print(x_train[:3])
sc = StandardScaler()
sc.fit(x_test)
sc.fit(x_train)
x_train = sc.transform(x_train)
x_test = sc.transform(x_test) # 표준화 완성
print(x_train[:3])
# 표준화 값을 원래 값으로 복귀
# inver_x_train = sc.inverse_transform(x_train)
# print(inver_x_train[:3])
SVM ( Support Vector Machine / 서포트 벡터 머신 ) 모델 작성 부분
# SVM 모델
from sklearn import svm
#model = svm.SVC()
#model = svm.SVC(C=1)
model = svm.LinearSVC(C=1)
model.fit(x_train, y_train) # 지도학습
<동일 뒷부분>
더보기
# 분류 예측
y_pred = model.predict(x_test) # 검정자료는 test
print('예측값 : ', y_pred)
print('예측값 : ', y_test)
# 분류 정확도
print('총 개수 : %d, 오류수 : %d'%(len(y_test), (y_test != y_pred).sum()))
print()
print('분류 정확도 출력1 : %.3f'%accuracy_score(y_test, y_pred))
con_mat = pd.crosstab(y_test, y_pred, rownames = ['예측치'], colnames=['실제치'])
print(con_mat)
print('분류 정확도 출력2 : ', (con_mat[0][0] + con_mat[1][1] + con_mat[2][2]) / len(y_test))
print('분류 정확도 출력3 : ', model.score(x_test, y_test))
print('분류 정확도 출력4 : ', model.score(x_train, y_train))
# 새로운 값으로 예측
new_data = np.array([[5.1, 2.4], [1.1, 1.4], [8.1, 8.4]])
# 표준화
sc.fit(new_data)
new_data = sc.transform(new_data)
new_pred = model.predict(new_data)
print('새로운 값으로 예측 : ', new_pred) # 새로운 값으로 예측 : [1 0 2]
#* 붓꽃 자료에 대한 로지스틱 회귀 결과를 차트로 그리기 *
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib import font_manager, rc
plt.rc('font', family='malgun gothic')
plt.rcParams['axes.unicode_minus']= False
def plot_decision_region(X, y, classifier, test_idx=None, resolution=0.02, title=''):
markers = ('s', 'x', 'o', '^', 'v') # 점 표시 모양 5개 정의
colors = ('r', 'b', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#print('cmap : ', cmap.colors[0], cmap.colors[1], cmap.colors[2])
# decision surface 그리기
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 0].min() - 1, X[:, 0].max() + 1
xx, yy = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
# xx, yy를 ravel()를 이용해 1차원 배열로 만든 후 전치행렬로 변환하여 퍼셉트론 분류기의
# predict()의 인자로 입력하여 계산된 예측값을 Z로 둔다.
Z = classifier.predict(np.array([xx.ravel(), yy.ravel()]).T)
Z = Z.reshape(xx.shape) # Z를 reshape()을 이용해 원래 배열 모양으로 복원한다.
# X를 xx, yy가 축인 그래프 상에 cmap을 이용해 등고선을 그림
plt.contourf(xx, yy, Z, alpha=0.5, cmap=cmap)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
X_test = X[test_idx, :]
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl, 0], y=X[y==cl, 1], c=cmap(idx), marker=markers[idx], label=cl)
if test_idx:
X_test = X[test_idx, :]
plt.scatter(X_test[:, 0], X_test[:, 1], c=[], linewidth=1, marker='o', s=80, label='testset')
plt.xlabel('꽃잎 길이')
plt.ylabel('꽃잎 너비')
plt.legend(loc=2)
plt.title(title)
plt.show()
x_combined_std = np.vstack((x_train, x_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_region(X=x_combined_std, y=y_combined, classifier=model, test_idx=range(105, 150), title='scikit-learn제공') 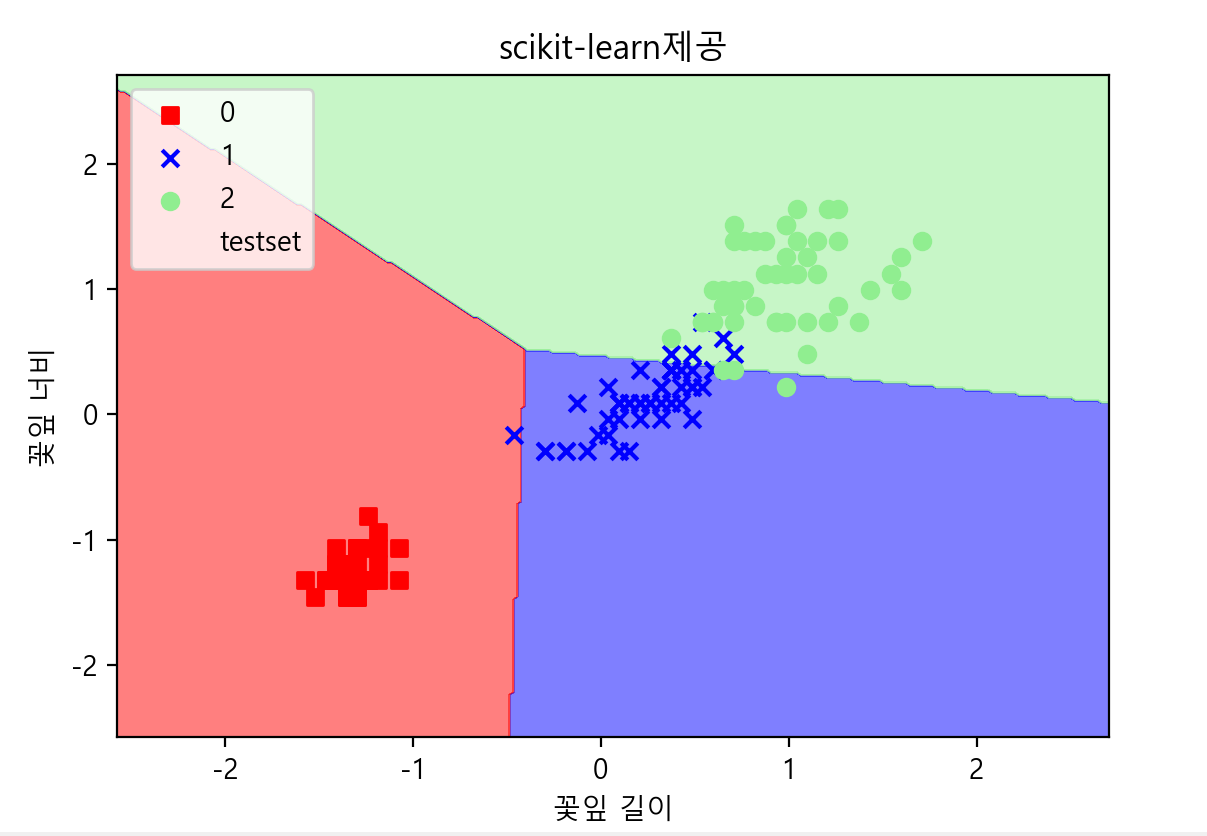
3. Random Forest
<동일 앞부분>
더보기
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection._split import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
iris = datasets.load_iris() # Iris 데이터 불러오기
print(iris.data[:3])
print(np.corrcoef(iris.data[:, 2], iris.data[:, 3])) # 상관관계 보기
"""
[[1. 0.96286543]
[0.96286543 1. ]]
"""
x = iris.data[:, [2, 3]] # feature(독립변수, x) : petal length, petal width
y = iris.target # label, class
print(type(x), type(y), x.shape, y.shape) # x는 2차원(150, 2) y는 1차원(150,)
print(set(y)) # {0, 1, 2}
print('-----------------train / test 분리 - 오버피팅(과적합)방지-----------------------')
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state = 0)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (105, 2) (45, 2) (105,) (45,)
# scaling(표준화)
print(x_train[:3])
sc = StandardScaler()
sc.fit(x_test)
sc.fit(x_train)
x_train = sc.transform(x_train)
x_test = sc.transform(x_test) # 표준화 완성
print(x_train[:3])
# 표준화 값을 원래 값으로 복귀
# inver_x_train = sc.inverse_transform(x_train)
# print(inver_x_train[:3])
RandomForest (랜덤 포레스트) 모델 작성 부분
# RandomForestClassifier 모델
from sklearn.ensemble import RandomForestClassifier
model= RandomForestClassifier(n_estimators = 500, criterion = 'entropy', n_jobs = 2)#n_jobs는 병렬처리
model.fit(x_train, y_train)
<동일 뒷부분>
더보기
# 분류 예측
y_pred = model.predict(x_test) # 검정자료는 test
print('예측값 : ', y_pred)
print('예측값 : ', y_test)
# 분류 정확도
print('총 개수 : %d, 오류수 : %d'%(len(y_test), (y_test != y_pred).sum()))
print()
print('분류 정확도 출력1 : %.3f'%accuracy_score(y_test, y_pred))
con_mat = pd.crosstab(y_test, y_pred, rownames = ['예측치'], colnames=['실제치'])
print(con_mat)
print('분류 정확도 출력2 : ', (con_mat[0][0] + con_mat[1][1] + con_mat[2][2]) / len(y_test))
print('분류 정확도 출력3 : ', model.score(x_test, y_test))
print('분류 정확도 출력4 : ', model.score(x_train, y_train))
# 새로운 값으로 예측
new_data = np.array([[5.1, 2.4], [1.1, 1.4], [8.1, 8.4]])
# 표준화
sc.fit(new_data)
new_data = sc.transform(new_data)
new_pred = model.predict(new_data)
print('새로운 값으로 예측 : ', new_pred) # 새로운 값으로 예측 : [1 0 2]
#* 붓꽃 자료에 대한 로지스틱 회귀 결과를 차트로 그리기 *
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib import font_manager, rc
plt.rc('font', family='malgun gothic')
plt.rcParams['axes.unicode_minus']= False
def plot_decision_region(X, y, classifier, test_idx=None, resolution=0.02, title=''):
markers = ('s', 'x', 'o', '^', 'v') # 점 표시 모양 5개 정의
colors = ('r', 'b', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#print('cmap : ', cmap.colors[0], cmap.colors[1], cmap.colors[2])
# decision surface 그리기
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 0].min() - 1, X[:, 0].max() + 1
xx, yy = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
# xx, yy를 ravel()를 이용해 1차원 배열로 만든 후 전치행렬로 변환하여 퍼셉트론 분류기의
# predict()의 인자로 입력하여 계산된 예측값을 Z로 둔다.
Z = classifier.predict(np.array([xx.ravel(), yy.ravel()]).T)
Z = Z.reshape(xx.shape) # Z를 reshape()을 이용해 원래 배열 모양으로 복원한다.
# X를 xx, yy가 축인 그래프 상에 cmap을 이용해 등고선을 그림
plt.contourf(xx, yy, Z, alpha=0.5, cmap=cmap)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
X_test = X[test_idx, :]
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl, 0], y=X[y==cl, 1], c=cmap(idx), marker=markers[idx], label=cl)
if test_idx:
X_test = X[test_idx, :]
plt.scatter(X_test[:, 0], X_test[:, 1], c=[], linewidth=1, marker='o', s=80, label='testset')
plt.xlabel('꽃잎 길이')
plt.ylabel('꽃잎 너비')
plt.legend(loc=2)
plt.title(title)
plt.show()
x_combined_std = np.vstack((x_train, x_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_region(X=x_combined_std, y=y_combined, classifier=model, test_idx=range(105, 150), title='scikit-learn제공') 
4. Naïve Bayes Classification
<동일 앞부분>
더보기
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection._split import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
iris = datasets.load_iris() # Iris 데이터 불러오기
print(iris.data[:3])
print(np.corrcoef(iris.data[:, 2], iris.data[:, 3])) # 상관관계 보기
"""
[[1. 0.96286543]
[0.96286543 1. ]]
"""
x = iris.data[:, [2, 3]] # feature(독립변수, x) : petal length, petal width
y = iris.target # label, class
print(type(x), type(y), x.shape, y.shape) # x는 2차원(150, 2) y는 1차원(150,)
print(set(y)) # {0, 1, 2}
print('-----------------train / test 분리 - 오버피팅(과적합)방지-----------------------')
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state = 0)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (105, 2) (45, 2) (105,) (45,)
# scaling(표준화)
print(x_train[:3])
sc = StandardScaler()
sc.fit(x_test)
sc.fit(x_train)
x_train = sc.transform(x_train)
x_test = sc.transform(x_test) # 표준화 완성
print(x_train[:3])
# 표준화 값을 원래 값으로 복귀
# inver_x_train = sc.inverse_transform(x_train)
# print(inver_x_train[:3])
Naïve Bayes ( 나이브 베이즈 ) 분류 모델 작성 부분
# Naive Bayes Classification Model
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(x_train, y_train) # 지도학습
<동일 뒷부분>
더보기
# 분류 예측
y_pred = model.predict(x_test) # 검정자료는 test
print('예측값 : ', y_pred)
print('예측값 : ', y_test)
# 분류 정확도
print('총 개수 : %d, 오류수 : %d'%(len(y_test), (y_test != y_pred).sum()))
print()
print('분류 정확도 출력1 : %.3f'%accuracy_score(y_test, y_pred))
con_mat = pd.crosstab(y_test, y_pred, rownames = ['예측치'], colnames=['실제치'])
print(con_mat)
print('분류 정확도 출력2 : ', (con_mat[0][0] + con_mat[1][1] + con_mat[2][2]) / len(y_test))
print('분류 정확도 출력3 : ', model.score(x_test, y_test))
print('분류 정확도 출력4 : ', model.score(x_train, y_train))
# 새로운 값으로 예측
new_data = np.array([[5.1, 2.4], [1.1, 1.4], [8.1, 8.4]])
# 표준화
sc.fit(new_data)
new_data = sc.transform(new_data)
new_pred = model.predict(new_data)
print('새로운 값으로 예측 : ', new_pred) # 새로운 값으로 예측 : [1 0 2]
#* 붓꽃 자료에 대한 로지스틱 회귀 결과를 차트로 그리기 *
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib import font_manager, rc
plt.rc('font', family='malgun gothic')
plt.rcParams['axes.unicode_minus']= False
def plot_decision_region(X, y, classifier, test_idx=None, resolution=0.02, title=''):
markers = ('s', 'x', 'o', '^', 'v') # 점 표시 모양 5개 정의
colors = ('r', 'b', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#print('cmap : ', cmap.colors[0], cmap.colors[1], cmap.colors[2])
# decision surface 그리기
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 0].min() - 1, X[:, 0].max() + 1
xx, yy = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
# xx, yy를 ravel()를 이용해 1차원 배열로 만든 후 전치행렬로 변환하여 퍼셉트론 분류기의
# predict()의 인자로 입력하여 계산된 예측값을 Z로 둔다.
Z = classifier.predict(np.array([xx.ravel(), yy.ravel()]).T)
Z = Z.reshape(xx.shape) # Z를 reshape()을 이용해 원래 배열 모양으로 복원한다.
# X를 xx, yy가 축인 그래프 상에 cmap을 이용해 등고선을 그림
plt.contourf(xx, yy, Z, alpha=0.5, cmap=cmap)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
X_test = X[test_idx, :]
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl, 0], y=X[y==cl, 1], c=cmap(idx), marker=markers[idx], label=cl)
if test_idx:
X_test = X[test_idx, :]
plt.scatter(X_test[:, 0], X_test[:, 1], c=[], linewidth=1, marker='o', s=80, label='testset')
plt.xlabel('꽃잎 길이')
plt.ylabel('꽃잎 너비')
plt.legend(loc=2)
plt.title(title)
plt.show()
x_combined_std = np.vstack((x_train, x_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_region(X=x_combined_std, y=y_combined, classifier=model, test_idx=range(105, 150), title='scikit-learn제공') 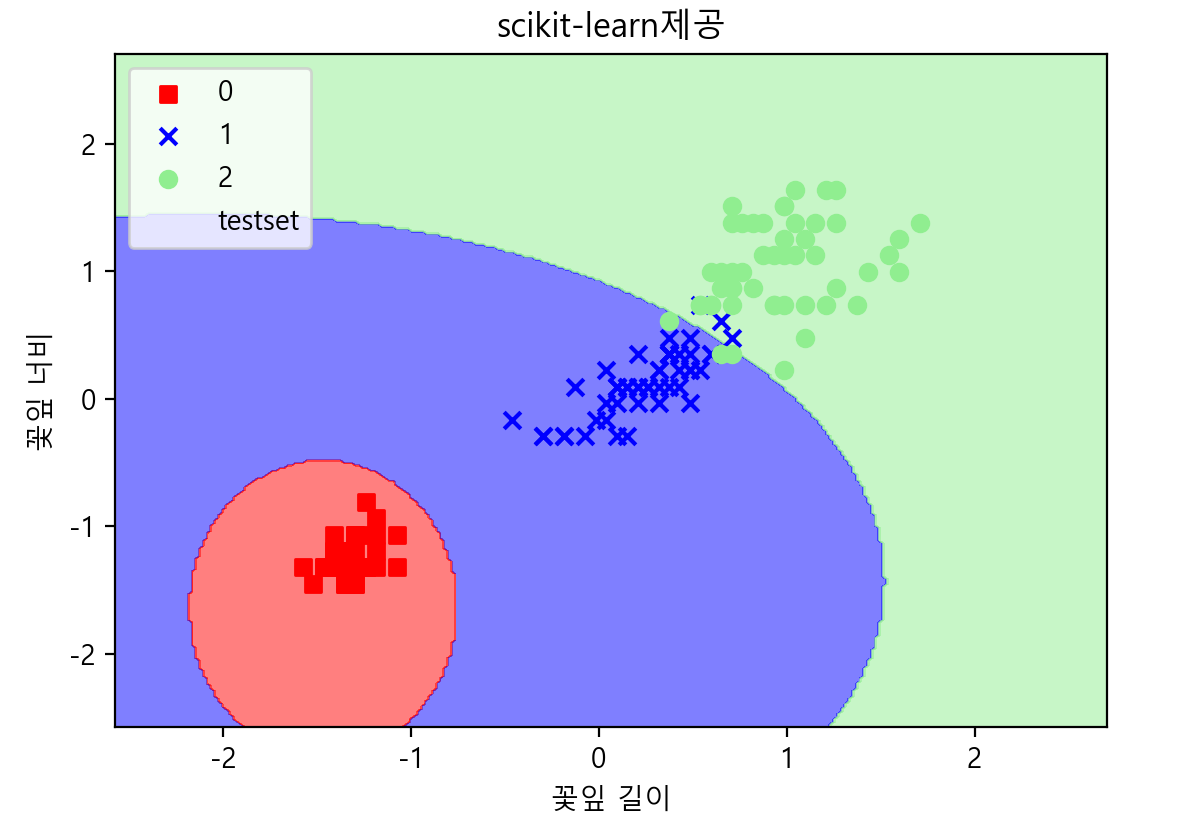
5. Decision Tree
<동일 앞부분>
더보기
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection._split import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
iris = datasets.load_iris() # Iris 데이터 불러오기
print(iris.data[:3])
print(np.corrcoef(iris.data[:, 2], iris.data[:, 3])) # 상관관계 보기
"""
[[1. 0.96286543]
[0.96286543 1. ]]
"""
x = iris.data[:, [2, 3]] # feature(독립변수, x) : petal length, petal width
y = iris.target # label, class
print(type(x), type(y), x.shape, y.shape) # x는 2차원(150, 2) y는 1차원(150,)
print(set(y)) # {0, 1, 2}
print('-----------------train / test 분리 - 오버피팅(과적합)방지-----------------------')
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state = 0)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (105, 2) (45, 2) (105,) (45,)
# scaling(표준화)
print(x_train[:3])
sc = StandardScaler()
sc.fit(x_test)
sc.fit(x_train)
x_train = sc.transform(x_train)
x_test = sc.transform(x_test) # 표준화 완성
print(x_train[:3])
# 표준화 값을 원래 값으로 복귀
# inver_x_train = sc.inverse_transform(x_train)
# print(inver_x_train[:3])
Decision Tree ( 의사결정 나무 ) 모델 작성 부분
# 의사결정 나무
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(criterion = 'entropy', max_depth = 5)
model.fit(x_train, y_train)
<동일 뒷부분>
더보기
# 분류 예측
y_pred = model.predict(x_test) # 검정자료는 test
print('예측값 : ', y_pred)
print('예측값 : ', y_test)
# 분류 정확도
print('총 개수 : %d, 오류수 : %d'%(len(y_test), (y_test != y_pred).sum()))
print()
print('분류 정확도 출력1 : %.3f'%accuracy_score(y_test, y_pred))
con_mat = pd.crosstab(y_test, y_pred, rownames = ['예측치'], colnames=['실제치'])
print(con_mat)
print('분류 정확도 출력2 : ', (con_mat[0][0] + con_mat[1][1] + con_mat[2][2]) / len(y_test))
print('분류 정확도 출력3 : ', model.score(x_test, y_test))
print('분류 정확도 출력4 : ', model.score(x_train, y_train))
# 새로운 값으로 예측
new_data = np.array([[5.1, 2.4], [1.1, 1.4], [8.1, 8.4]])
# 표준화
sc.fit(new_data)
new_data = sc.transform(new_data)
new_pred = model.predict(new_data)
print('새로운 값으로 예측 : ', new_pred) # 새로운 값으로 예측 : [1 0 2]
#* 붓꽃 자료에 대한 로지스틱 회귀 결과를 차트로 그리기 *
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib import font_manager, rc
plt.rc('font', family='malgun gothic')
plt.rcParams['axes.unicode_minus']= False
def plot_decision_region(X, y, classifier, test_idx=None, resolution=0.02, title=''):
markers = ('s', 'x', 'o', '^', 'v') # 점 표시 모양 5개 정의
colors = ('r', 'b', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#print('cmap : ', cmap.colors[0], cmap.colors[1], cmap.colors[2])
# decision surface 그리기
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 0].min() - 1, X[:, 0].max() + 1
xx, yy = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
# xx, yy를 ravel()를 이용해 1차원 배열로 만든 후 전치행렬로 변환하여 퍼셉트론 분류기의
# predict()의 인자로 입력하여 계산된 예측값을 Z로 둔다.
Z = classifier.predict(np.array([xx.ravel(), yy.ravel()]).T)
Z = Z.reshape(xx.shape) # Z를 reshape()을 이용해 원래 배열 모양으로 복원한다.
# X를 xx, yy가 축인 그래프 상에 cmap을 이용해 등고선을 그림
plt.contourf(xx, yy, Z, alpha=0.5, cmap=cmap)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
X_test = X[test_idx, :]
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl, 0], y=X[y==cl, 1], c=cmap(idx), marker=markers[idx], label=cl)
if test_idx:
X_test = X[test_idx, :]
plt.scatter(X_test[:, 0], X_test[:, 1], c=[], linewidth=1, marker='o', s=80, label='testset')
plt.xlabel('꽃잎 길이')
plt.ylabel('꽃잎 너비')
plt.legend(loc=2)
plt.title(title)
plt.show()
x_combined_std = np.vstack((x_train, x_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_region(X=x_combined_std, y=y_combined, classifier=model, test_idx=range(105, 150), title='scikit-learn제공')
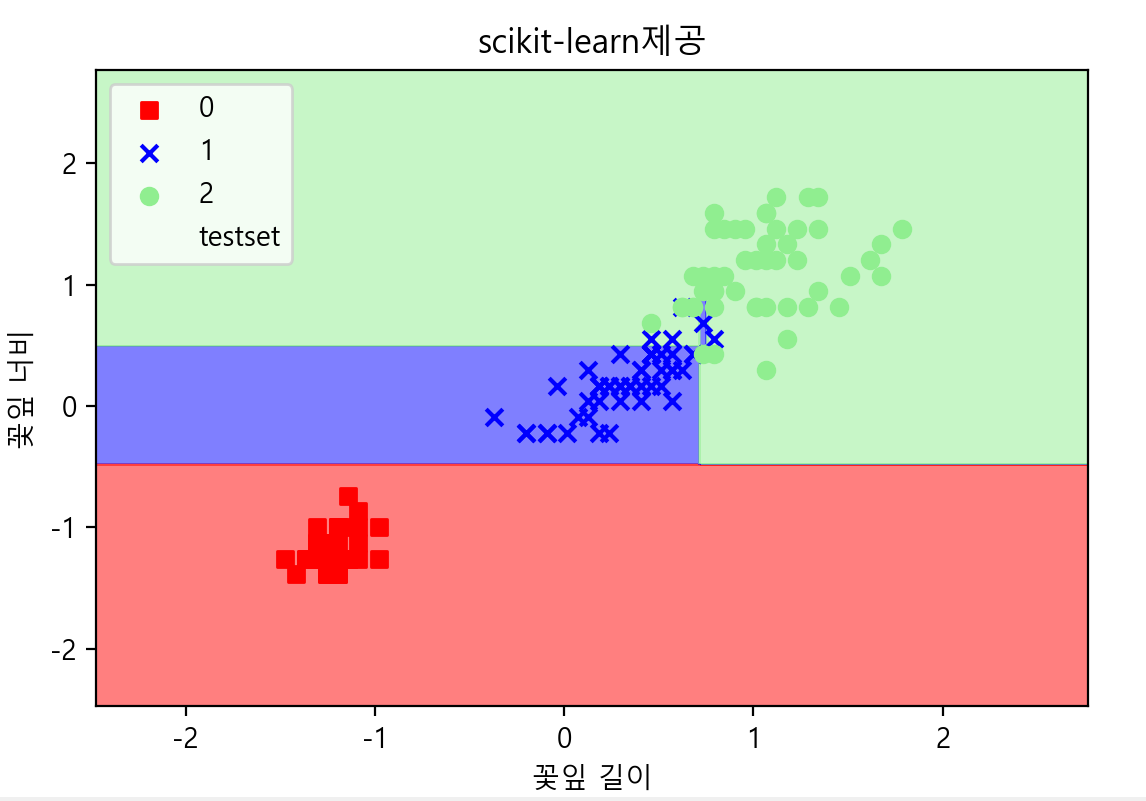
tree - 추가)
print('-------------------------특성 중요도-------------------------')
# 전체 트리 결정에 각 특성이 어느정도 중요한지 평가
print('특성 중요도 : \n{}'.format(model.feature_importances_))
def plot_feature_importances(model):
n_features = x.data.shape[1]
plt.barh(range(n_features), model.feature_importances_,align='center')
plt.yticks(range(n_features),iris.feature_names)
plt.xlabel('특성중요도')
plt.ylabel('특성')
plt.ylim(-1, n_features)
plot_feature_importances(model)
plt.show()
print('-----------------------graphviz-----------------------')
from sklearn import tree
from io import StringIO
import pydotplus
dot_data = StringIO() # 파일 흉내만 낸다
tree.export_graphviz(model, out_file = dot_data,
feature_names = iris.feature_names[2:4])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('tree2.png')
import matplotlib.pyplot as plt
img = plt.imread('tree2.png')
plt.imshow(img)
plt.show()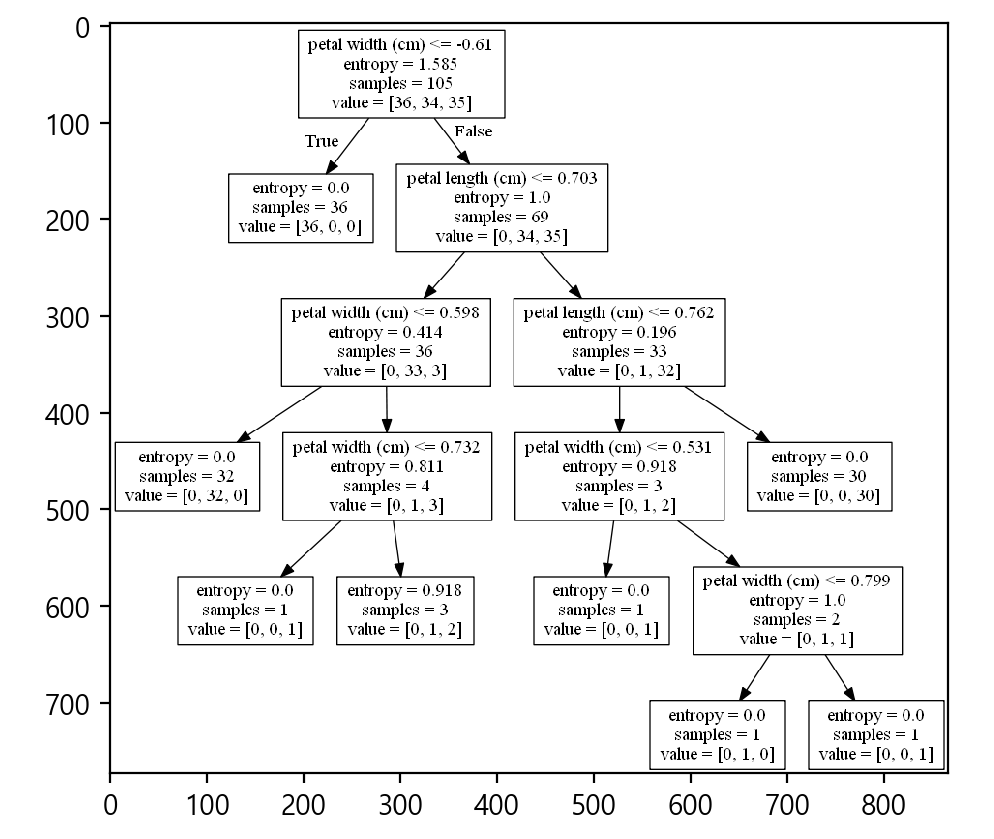
728x90
'Machine Learning' 카테고리의 다른 글
| 상관 분석 / Correlation Analysis / 피어슨 / 스피어만 / 켄달 상관계수 (0) | 2021.03.30 |
|---|---|
| 머신러닝 / 선형회귀분석 / 모델 작성후 추정치 얻기 (0) | 2021.03.11 |
| 머신러닝 / Python / Pandas 판다스 / MariaDB 연결 (0) | 2021.03.11 |
| 머신러닝 / Python / ANOVA(analysis of variance) / 분산분석 (0) | 2021.03.11 |
| 머신러닝 / 웹크롤링 / 형태소분석 / WordCloud 차트 출력하기 (2) | 2021.03.10 |


댓글